機械学習:医療の未来
医療、特に医療診断におけるフォトニクスの未来が機械学習にかかっていることに疑いの余地はないが、それは道具であって魔法の杖ではないことを覚えておく必要がある。
本誌ではこの1年間、ラマン分光法、多光子励起顕微鏡法、そして直近では離散周波数赤外(discrete frequency in frared:DFIR)顕微鏡法と、医療診断に変革をもたらすであろう複数のフォトニクス手法を取り上げてきた。これらの技術によってより迅速で正確な情報が医師に提供されて、患者の治療方針に関するより良い判断が可能になる可能性について、説明してきた。しかし、そうした技術を研究室から臨床現場に移すことに伴う課題については、あまり議論してこなかった。トランスレーショナル医療の世界では、これは「valley of death」(デスバレー)と呼ばれている。非臨床と臨床の境界を渡り切ることのできる技術は、非常に少ないためである。バイオフォトニクスも例外ではない。実際、米カリフォルニア大アーバイン校(University of California Irvine)のベックマンレーザ研究所(Beckman Laser Institute and Medical Clinic)所長を務めるブルース・トロンバーグ氏(Bruce Tromberg) は、「2020 BiOS Photonics West」カンファレンスで、医療フォトニクスにおける起業家精神をテーマとした発表の中で、「デスバレーは1つではない。多数存在する」と述べた(1)。
過去の経験から言って、先進的な光学技術の臨床応用における最大の課題の1つは、より広範な母集団に対する特異性を確認するために膨大な量のデータが必要になることである。大規模な応用は、まさに大業と言って過言ではないことが実証されている。これを示すために、研究者がラマン分光法を使用して、癌組織と良性組織のサンプルを識別する状況を考えてみよう。
この技術を研究室から臨床現場へと移行させるには、幅広い人口統計層にわたる、数千人とまではいかずとも、数百人の患者からサンプルを収集する必要がある。それらのサンプルをラマン分光計で測定し、資格を持つ病理学者による交差検証とラベル付けの後、前処理を経て、多変量分類アルゴリズムに入力する。長年にわたり、病理学と演算の両方の要件が克服不可能だとみられていた。しかし、幸いなことにこの数年間で、機械学習が進歩し、病理学コミュニティの中で自動化に対する認識が高まったことが(2)、デスバレーを越えるための橋渡しになりそうである。
「複数の手法をいくつかの医療関連の機械学習に適用してきた経験から、群を抜いて最大の問題は、豊富で適切
なデータセットへのアクセスである。人間がラベル付けしたデータは一般的に小規模で、人的ミスによって医療デジタルデータ精度は90%を大きく下回る場合があるため、それも制約になる可能性がある。幸い、より小規模なデータセットで、非常に高い精度が得られる、新しいディープラーニング手法が登場しており、それは、AIがそうした従来の障壁を克服していることを意味している」と、加Stream.ML社とバイオストリーム・ダイアグノスティックス社(Bio-Stream Diagnostics)の最高経営責任者(CEO)を務めるジョン・マーフィー氏(John Murphy)は述べた。
機械学習の基礎
機械学習は、医療におけるフォトニクスの未来のまさに鍵となる可能性があるため、公開文献からの具体的な例を詳しく見ていく前に、まずは機械学習について理解することが不可欠である。最も基本的なレベルにおいて機械学習は、データを取り込み、それを基に学習し、その知識を利用してパターンを検出することを目的に設計された、あらゆるアルゴリズム集合を指す、包括的な語である。
明らかにその定義は、自動イメージング、スペクトル、ハイパースペクトル診断システムの目的に、これ以上ないほど適合している。しかし、その背景にある仕組みについては、その単語からは直感的には理解できない。機械学習がフォトニック診断をどのように支援するかを本当に把握するための唯一の手段は、その根底にあるアルゴリズムを理解することである。
生体系に大まかに基づくニューラルネットワークが、機械学習技術の基礎を成している。しかし、生物学やコンピュータ科学の専門家でなければ、ニューラルネットワークの基本的理解を得ることはできないと、多くの人が思い込んでいるかもしれないが、そうではない。実際、メリット関数を最適化したことのある光学エンジニアならば誰でも、ニューラルネットワークの構築に必要なほとんどの力仕事を、気づかぬうちに既に経験している。
すべてのニューラルネットワークの根底にある基本原理は、ニューロン活性化の概念である。
これもまた複雑に聞こえるが、実際にはそうではない。最も簡単な考え方は、ニューロンは行列要素で、その活性化は各要素の値と考えることである。例えば、図1のニューラルネットワークにおいて、入力層のニューロンはそれぞれ、スペクトル内のピクセル番号に対応する。従って、正規化されたピクセル値が入力の活性化に相当する。入力層の各ニューロンの出力は、2つめの層の各ニューロンに供給される。出力関数の具体的な数学的詳細は、それほど重要ではない。重要なのは、層内の各ニューロンの活性化が、1つ前の層のすべてのニューロンからの出力の加重合計によって決まるということである。
入力スペクトル(図1)は4000個のニューロン(ピクセル)、次の層は4個のニューロンで構成されると仮定すると、2つめの層のニューロンの最終的な活性化状態を計算するために、合計1万6000個の重みを割り当てなければならない。その処理は手作業では不可能で、それを終えてもまだ3つめの層には到達できない。そこで登場するのが機械学習である。
ニューラルネットワークでは、すべての重みが完全にランダムな状態でスタートし、ユーザーは、トレーニング(学習)として知られるプロセスを通した、出力層にのみ注目すればよい。トレーニングにおいて、ユーザーの作業は、既知のスペクトルと既知の出力(癌か良性かなど)を入力することである。2つの出力ノードのうちの一方を癌組織、もう一方を良性組織として割り当てることによって、これを行う。そう
すると、最小二乗法に基づくメリット関数(機械学習ではコスト関数と呼ばれる)と最急降下アルゴリズムを使用して、(誤差逆伝播法によって)個々の重みを最適化することにより、システムは、癌組織のスペクトルが入力される度に確実に適切な出力ニューロンを活性化して、それ以外は活性化しないために、どの重みが必要であるかを学習することができる。
人間がラベル付けした十分に大きなデータセットをネットワークに供給する以外に人間の関与はないため、これは、実際の機械学習が行われる、ほぼブラインドの(中身が見えない)プロセスである。そのため、ネットワーク内のすべての中間層は隠れ層と呼ばれる。これは、ニューラルネットワークを究極的に簡素化した例であり、現時点で最もよく利用されているアーキテクチュアでもないことに注意してほしい。
このような用途に対して現在最も広く利用されているのは、畳み込みニューラルネットワークである。それでも上記の構造は、ニューラルネットワークと機械学習の動作の仕組みや、スペクトルや画像分類の自動化に対するこのプラットフォームの能力を、視覚的に説明するものとして優れた役割を果たしている。
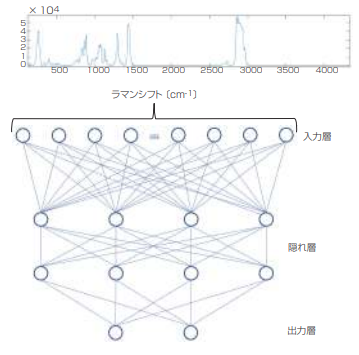
図1 スペクトル処理に対するシンプルなニューラル
ネットワークの構造図。それぞれ 4個のニューロンで構成される2つの隠れ層と、バイナリの出力層で構成されている。
(もっと読む場合は出典元へ)
出典元
http://ex-press.jp/wp-content/uploads/2022/01/032-035_ft_machine_learning.pdf