フォトニック集積はどのようにAIを加速できるか
AIは自動運転車などのポテンシャルの期待に応えるため、大幅に速度を上げる必要がある。フォトニック集積はその溝を埋める可能性がある。
古参の人たちは光コンピューティングのすべてが新しいわけではないことを知っている。合成開口レーダーデータのフーリエ変換によって軍事地図を生成する光学処理は、機密扱いとして1950年代に成功した。しかし最終的に成功を収めたのは電子高速フーリエ変換だった。1980年代、故ジョン・コーフィールド氏(John Caulfield)は、新世代の光コンピューティングが、我々が想像もしなかったことをどのように実行できるかを教えてくれたが、つじつまを合わせることはできなかった。またしても、電子工学はより速く、より良く、より安価であることが証明された。半導体の機構がナノメートルスケールにまで縮小し、ムーアの法則が限界を迎えている今、次世代の集積フォトニクスは、電子工学が提供できる以上に人工知能(Artificial Intelligence:AI)の速度と処理能力を高める可能性がある。
AIの探求
AIには、実現が困難であることが証明された独自の長い見通しの歴史がある。AIのルーツは、文学上のサイエンス・フィクションに由来する。アイザック・アシモフの有名なロボットの話は、若き教授として1960年代初頭にMIT人工知能研究所を立ち上げた、マービン・ミンスキー氏(Marvin Minsky)に影響を与えた。光コンピューティングと同様に、AIは軌道に乗るのが遅く、1980年代から1990年代初頭にかけて「AIの冬」に見舞われた。
その復活は、人間の脳のようにプロセッサ間に大規模の相互接続を持つニューラルネットワークを使用し、大量の情報を収集及び分析するようコンピュータをプログラムする機械学習からもたらされた。機械学習システムは、スパムメールのフィルタリングから「Netflix(ネットフリックス)」における映画の推薦まで、さまざまなアプリケーションを見つけたが、最も有名な用途は、碁やチェスなどの複雑なゲームで人間を打ち負かすことだ。
深層学習は、より複雑なニューラルネットワークを使用して、音声認識や自動運転などのより複雑なタスクに取り組むことにより、機械学習を拡張する。ただし深層学習では、行列ベクトル操作などの複雑なプロセスを使用して大量の情報を処理する必要があり、電子コンピュータは急速に増加する需要に対応できない。開発者たちは、必要とされるスピードとパワーの増大を提供できるシリコンフォトニクスを探している。
「異質の」知能
ニューラルネットワークは機械学習の設計に影響を与えたものの、AIは人間の頭脳のように機能することはない。機械学習では、「コア計算アルゴリズムはプログラマーによって完全に提供されるわけではないが、経験を通じてコンピュータシステムにより自動的に改善または生成される」と現在、英ケンブリッジ大(University of Cambridge)に所属するチーシャン・チェン氏(Qixiang Cheng)はレビュー記事で述べている(1)。機械学習システムは、データのパターンを認識するように設計された特別なアルゴリズムを使用して入力情報を処理することにより学習する。多くの場合、画像が出発点になるが、システムは他の種類のデータも分析する。
AIは人とは異質の知性だと思うかもしれないが、異なるスキルを持っている。AIは、何度もプレイしてルールが明確に定義されたゲームで見事に機能し、我々が非常に知的であると考える人間のチャンピオンを打ち負かすことができる。ただし、AIは特定のタスク用に学習する必要があり、学習セットにない他のものを認識することはできない。AIのチェスチャンピオンはブロックの周りで車を運転することはできず、自動運転AIは、ホースが取り付けられ道路で停止してライトを点滅させている大型の赤いトラック、つまり消防車について、事前に学習していない限りどうしたらよいのかわからないだろう。人間はそれより順応性がある。
深層学習は、複数レベルの処理を備えたニューラルネットワークを使用し、より大きなデータセットを並べ替えることにより、機械学習を拡張する。例えばニューラルネットワークは鼻の形、髪の毛の色と髪型、目や肌の色、目の間の距離、その他の顔の特徴の位置など、顔を認識するために複数の要素を使用する場合がある。行列ベクトル乗算、畳み込み、フーリエ処理などのツールを使用した多くのレベルのデータの数学的処理は、音声認識、画像分類、自動運転車の運転などのアプリケーションで成功を収めている。
成功のためには、大量のデータを非常に迅速に処理する必要がある。運転はリアルタイムで行わなければならないことから特別な課題である。自動運転車は、道路の中央で止まり、道路を横切って移動する未知の物体を特定するまで待つことはできない。そのため、大量のデータを処理するときにはレイテンシ(遅延時間)が問題になる。現代の電子コンピューティングは、処理速度だけでなく高速で急速に増加していく消費電力においても実際的な限界に直面しており、設計者は数GHz以上で動作するよう半導体プロセッサを複数のコアに分割する必要がある。
開発者は、光並列処理、フォトニック集積、及びシリコンフォトニクスの組み合わせにより、遅延時間を減らし、自動運転車などのアプリケーションにおける深層学習への厳しい制限に対処することができると期待している。
AIのための集積シリコンフォトニクス
深層学習において最も複雑で時間のかかる操作は、行列とベクトルの乗算である。この乗算では、M行N列の行列にN次元のベクトル(X)が乗算される。入力データは電子的に供給され、光学フォームに変換されるため、フォトニック集積回路で乗算を実行できる。これにより、Y=K・XのフォームのM次元ベクトルが生成され、電子機器に返される。その出力は、システムで使用するため、さらに処理が必要になる場合がある。
行列の乗算には複数の操作が必要であり、光学の普通の並列処理で同時に実行できる。集積フォトニクスは、古いバルク光学技術よりもはるかに効率的である。光トランシーバは電子トランシーバより消費電力が少なく、光ニューラルネットワークを完全にトレーニングできれば、マトリックスをパッシブのままにして、さらに電力を消費することなく操作を続けることができる。光行列の乗算は、一般的に数GHzの電子クロック・レートよりもはるかに速い、約100GHzまで光検出率の値を押し上げることができる。
AI集積フォトニックチップの最も一般的な2つのコンポーネントは、マッハツェンダ干渉計(MachZehnder Inter ferometer:MZI)とマイクロリング共振器(Microring Resonator:MRR)で、 どちらも図1に示 されている。MZIの歴史は1世紀以上前にさかのぼる。左側の2つの入力が混合され、2つの並列のアームを通過する。ここで光が変調されて、右側の2つの出力間の分割が制御される。より最近に考案されたMRRは、サブ波長ギャップを介して光を他の光導波路に結合できる小さな導波路のリングである。共振は、整数の波がリングの長さに正確に適合する波長で、リングの長さに従って発生する。これらの2つの光ビルディングブロックを組み合わせると、変調器、
フィルタ、マルチプレクサ、スイッチ、及び演算器を作成できる。
マルチリング共振器とMZIは、FPGA( FieldProgrammable Gate Array)と組み合わせて、光ベクトル行列の乗算を実行できる。フォトニック深層学習システムは、操作の結果を使用してオブジェクトを学習及び認識し、純粋な電子システムが現在提供できるよりも高い処理能力と速度を提供することが期待される。
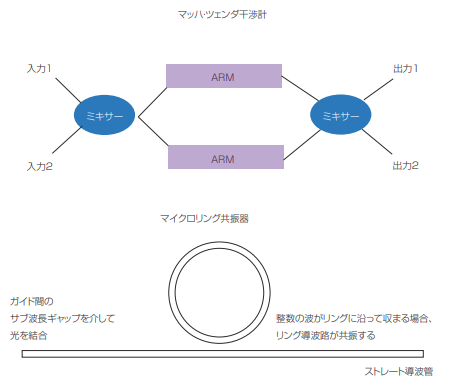
図1 集積フォトニクスの基本的な構成要素。(上)のZIは、光がアーム内でどのように変調されているかに応じて、2つの出力間で光を分割する。(下)のMRRは、整数の波がリングの周りで適合すると共振し、サブ波長ギャップを介して隣接する導波路に光を結合する
(もっと読む場合は出典元へ)
出典元
http://ex-press.jp/wp-content/uploads/2021/09/024-028_ft_future_photonics-1.pdf